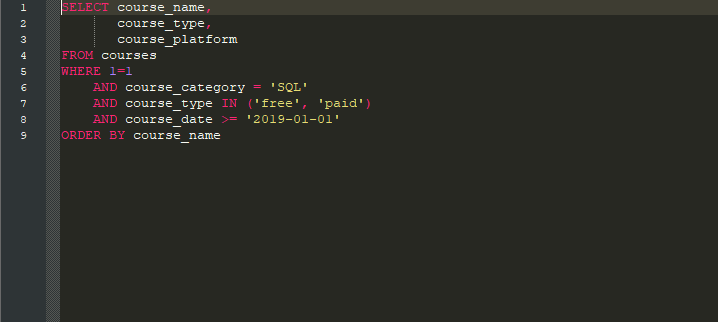
Structured Query Language (SQL) je jezik baziran na relacionoj algebri i dizajniran je za pristupanje i manipulisanju podacima koji se nalaze u bazama podataka. Razvijen pre više od 40 godina od...
Structured Query Language (SQL) je jezik baziran na relacionoj algebri i dizajniran je za pristupanje i manipulisanju podacima koji se nalaze u bazama podataka. Razvijen pre više od 40 godina od...
Posit (aka RStudio) predstavlja besplatan, open source IDE (integrated development environment) za R programski jezik koji se fokusira na statističku analizu. Kompanija je osnovana 2008. godine sa...

Tidyverse predstavlja kolekciju R biblioteka koje su namenjene pre svega za čišćenje, manipulaciju i vizualizaciju podataka. Kolekcija sadrži biblioteke dplyr, tibble, tidyr, purrr, ggplot2, readr. U...

Google Analytics je veoma koristan i moćan alat i ako se ne trudite da iskoristite njegove mogućnosti, definitivno mnogo propuštate. Bez obzira da li je vaš sajt prodajnog ili promotivnog karaktera...

Google analitika je jedna od najpopularnijih alatki za setup, reporting i analizu podataka koji se tiču sajta. Google Analytics takođe nudi besplatan pristup API (application programming interface)...

Svaki izveštaj u Google Analytics alatu je sastavljen od dimenzija i metrika. Postoji preko 400+ metrika i dimenzija koje su dostupne za pravljenje izveštaja ili segmenata. Dimenzije predstavljaju...

Mnogi u svom poslu koriste R ili MATLAB kada analiziraju podatke. Bez obzira što je R razvijen od strane statističara, u poslednjim godinama se nameće i programski jezik Python sa jako puno...