
Pandas predstavlja brzu i fleksibilnu open source biblioteku za Python programski jezik koja pruža visoke performanse za ceo proces analize podataka na jednostavan i intuitivan način.
Ima cilj da postane jedna od najmoćnijih i najfleksibilnijih open source alata za analizu i manipulaciju podataka. Namenjena je za sve Python korisnike koji žele da rade sa podacima i koriste moćan alat za to.
Pored biblioteka Matplotlib i NumPy, Pandas je jedna od najkorišćenijih kada je u pitanju data science oblast. Originalni autor je Wes McKinney a poslednja stabilna verzija je 0.20.1 koja je izašla u maju ove godine. Što se tiče korišćenja, potrebno je poznavanje osnova Python-a dok se iskustvo u korišćenju Pandas možete imati ali nije obavezno. Zvanična i vrlo opširna Pandas dokumentacija je na ovom linku.
UPDATE:
Tokom septembra je izašla vrlo zanimljiva statistika koja je vezana za saobraćaj na čuvenom Stack overflow-u a tiče se konkretno Python programskog jezika. Pandas biblioteka ima najveći rast od svih Python related tag-ova. Svakako više o analizi može te pročitati na ovom linku.
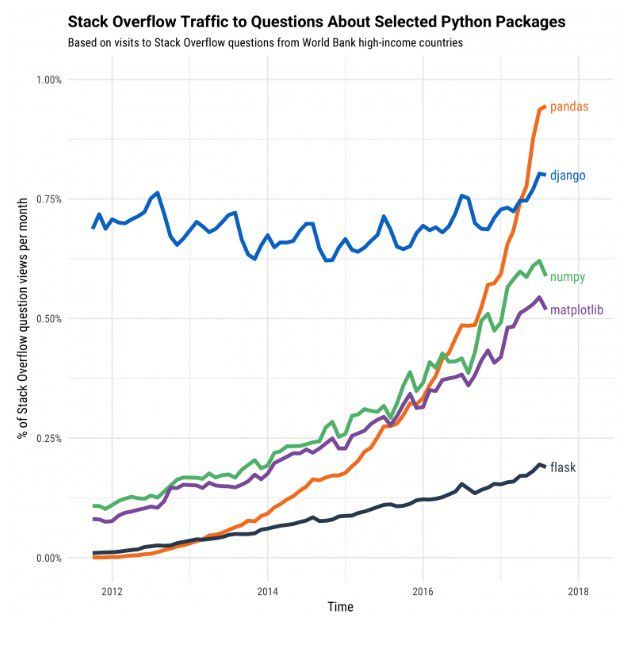
Python Pandas
Neke od osnovnih funkcionalnosti koje se mogu naći u besplatnoj Pandas biblioteci su:
- Import i export podataka u različitim formatima (CSV, Txt, Excel, SQL, HDF5)
- Statistika
- Indexiranje, sortiranje, rangiranje
- Čišćenje podataka
- Filtriranje
- Grupisanje (GroupBy)
- Pivot
- Rad sa vremenskim serijama (time series)
- Vizualizacija podataka
![]()
Karakteristike:
- Velika podrška i jaka zajednica
- Aktivno se razvija
- Ima opsežnu dokumentaciju
- Odlično radi sa ostalim bibliotekama kao na primer sa Scikit Learn za mašinsko učenje
- Izgrađena na NumPy što znači da je brza
Pandas struktura
Postoje dve primarne strukture podataka u Pandas:
- Series (1D – jednodimenzionalna)
- DataFrame ( 2D – dvodimenzionalna)
Pandas Series
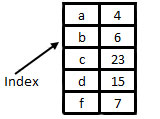
Series predstavlja 1D – jednodimenzionalni objekat slično koloni u tabeli ili kao NumPy array i ima mogućnost da skladišti bilo koji tip podataka gde dodeljuje index svakoj vrednosti u Series. Po default-u svaka vrednost će dobiti index label od 0 do N (gde je N veličina Series -1).
Pandas DataFrame
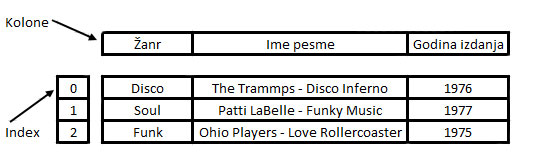
Za sve one koji su upoznati sa R programskim jezikom znaju da je data frame način za tabelarno skladištenje podataka.
DataFrame u Python-u je vrlo sličan, predstavlja tabelarnu strukturu podataka koja je definisana kao 2D – dvodimenzionalna struktura sa kolonama u redovima sa potencijalno različitim tipovima podataka (inicijalno se podaci skladište kao 2D ali DataFrame ima mogućnost da prikaze i manipuliše sa podacima koji imaju više dimenzija, 3D na primer…).
DataFrame je vrlo sličan i srodan spreadsheet-ovima, tabelama iz baze podataka ili data.frame objektu iz R-a. Takođe DataFrame se može posmatrati i kao grupa Series objekata koje dele isti index (imena kolona).
DataFrame se sastoji uglavnom od tri glavne komponente:
- podataka (Pandas DataFrame ili Series, NumPy ndarray ili 2D ndarray itd…)
- Index-a
- Kolona
import pandas as pd
df = pd.read_csv('movies.csv')
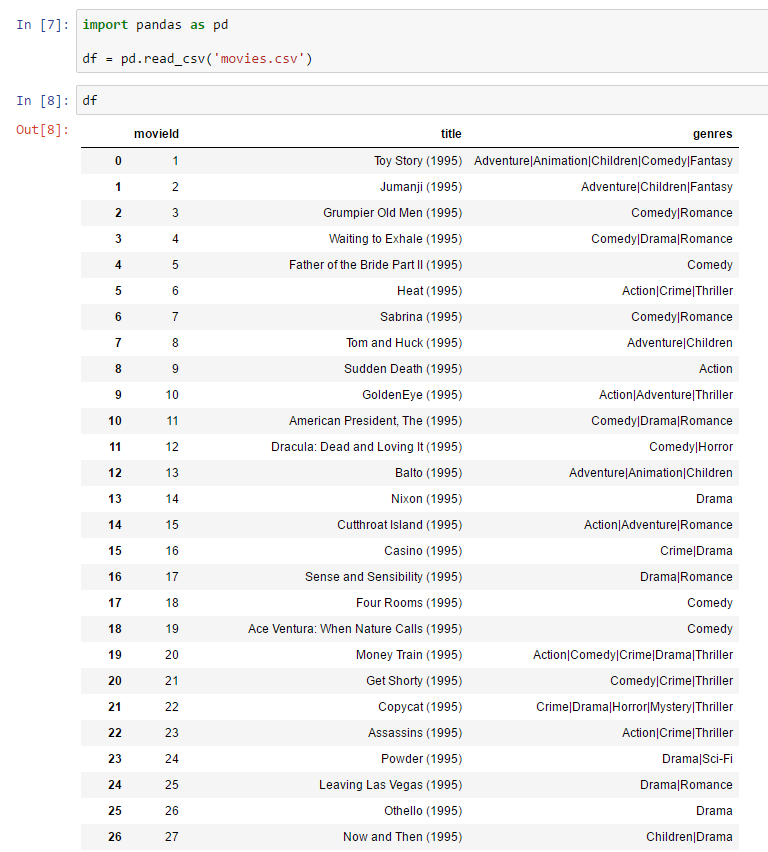
U nastavku i u daljim tekstovima ću se prevashodno fokusirati na Pandas DataFrame jer se on najčešće koristi.
Jupyter Notebook & Anaconda

U daljem tekstu ću koristiti Python 3.6 i Jupyter Notebook 5.0.0. i svakako predlažem da skinete Anaconda powered by Continuum Analytics, besplatnu vodeću data science platformu koje predstavlja distribuciju visokih performansi za Python i R i uključuje preko 100 najpopularnijih biblioteka iz programskih jezika Python, R, Scala.
Dodatno naravno možete pristupiti u preko 700 biblioteka koje se vrlo lako instaliraju kroz Anacondu.
Set podataka koji ću koristiti u primerima u nastavku je baza podataka MovieLens. Sastoji se od preko 20,000,000 miliona rejtinga na preko 27,000 filmova. Ovi podaci su kreirani od strane 138,493 korisnika koji su anonimni u periodu od preko 10 godina.
Importovanje i čitanje podataka
U većini slučajeva imaćete set podataka koji ćete želeti da učitate u DataFrame. Postoje nekoliko načina za to i u zavisnosti od vrste fajla koristi se odgovarajuća funkcija. Najčešće vrste fajlova koje se učitavaju su definitivno Comma-separated values (.csv) i Excel (.xlsx).
Pre svega potrebno je da se importuje biblioteka sa kojima će se raditi, u ovom slučaju to je Pandas.
Zvanični alijas zajednice i skraćenica za Pandas je pd dok je za DataFrame alijas df.
import pandas as pd
Fajl koji se koristi kao primer je .csv fajl. Kako bi se učitao, koristiće se funkcija iz nastavka koja će učitati fajl i uzvratit DataFrame. Isti princip važi i kada je Excel fajl u pitanju. Primeri koda su u nastavku.
df = pd.read_csv('movies.csv')
df = pd.read_excel('movies.xlsx')
Pregledanje i inspekcija podataka
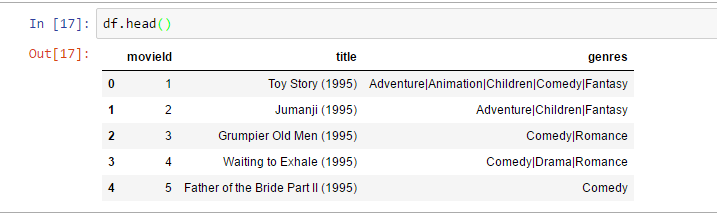
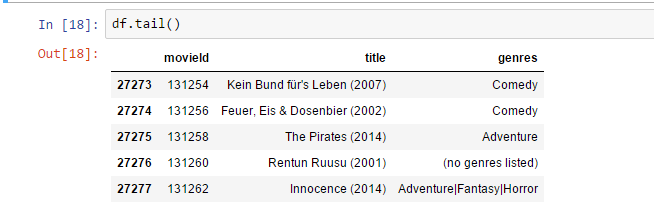
Kada se učita DataFrame, Pandas biblioteka ima nekoliko metoda kako se mogu inspektovati učitani podaci. Jedna od njih je head metoda koja uzvraća rezultat od prvih 5 redova učitanog fajla, dok tails metoda uzvraća poslednjih pet redova DataFrame-a.
df.head()
df.tail()
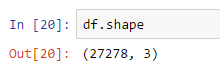
Takođe može da se vidi koliko je redova i kolona zapravo u učitanom DataFrame-u korišćenjem shape metode.
df.shape
Ono što je velika prednost Pandas je da dozvoljava kolone sa različitim tipovima podataka. Svakom redu je dodeljen index od 0 do N-1, gde je N broj redova koliko ima u DataFrame-u i ovo se dodeljuje po default-u ako nije drugačije precizirano (ovo može da se promeni, na primer da se u index stave vremenske serije ili ID).
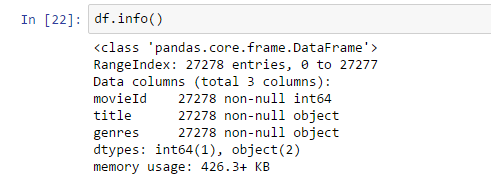
U DataFrame-u iz primera je recimo učitano ukupno 27,278 redova i svaki red ima index. Ukupno ima 3 kolone i takođe tu su informacije o tipovima podataka, koliko ih ima, koliko memorije zauzimaju itd.
df.info()
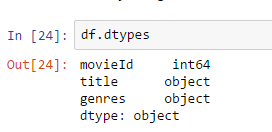
df.dtypes
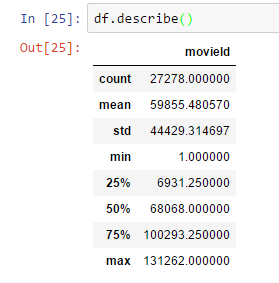
DataFrame takođe ima i describe metodu koja je odlična za brz uvid u osnovnu statistiku numeričkih kolona fajla koji je učitan. U importovanom fajlu koji je u primeru samo kolona movieid je numerička i obzirom da je ona ID vrednost, statistika za nju nije relevantna.
df.describe()
Zaključak
U ovom uvodu za Pandas biblioteku sam nabrojao osnovne funkcionalnosti i karakteristike. Takođe obuhvaćeni su primeri osnovnih metoda za učitavanje eksternih podataka uz njihvo osnovno ispitivanje.
Pandas biblioteka ima zaista mnogo korisnih funkcionalnosti i sve su vredne pažnje. Svakako verujem da će vas ovaj uvod dovoljno zaintrigirati i pomoći u daljem korišćenju Pandas i naravno Python programskog jezika uopšte.
Ako imate problem sa motivacijom za konstantno vežbanje i usavršavanje najbolji savet za to je da nađete temu koja vas interesuje i koja vas motiviše da vežbate ono što ste naučili i ono što tek planirate da naučite. To može da bude lični projekti i setovi podataka, Kaggle takmičenja, čitanje knjiga ili blogova, pristustvo meetup-ovima i konferencijama.
Kaggle takmičenja su neverovatno dobar način da se vežba sa već unapred definisanim problemom koji je potrebno da se reši. Takođe postoje mnogi online kursevi za učenje preko interneta i platforme kroz koje se uči u browser-u i o velikoj većini kada je u pitanju Python i data science sam pisao u ovom tekstu.
Za pitanja i komentare, slobodno pišite.
Srećno učenje!

